- 发布于
Linux 线程模型
- 作者

- 作者
- 霍浩东
- @huohaodong
用户线程与内核线程
想要理解 Linux 线程模型,首先要明确两个概念:用户线程(User Level Thread)和内核线程(Kernel Level Thread),如下所示:
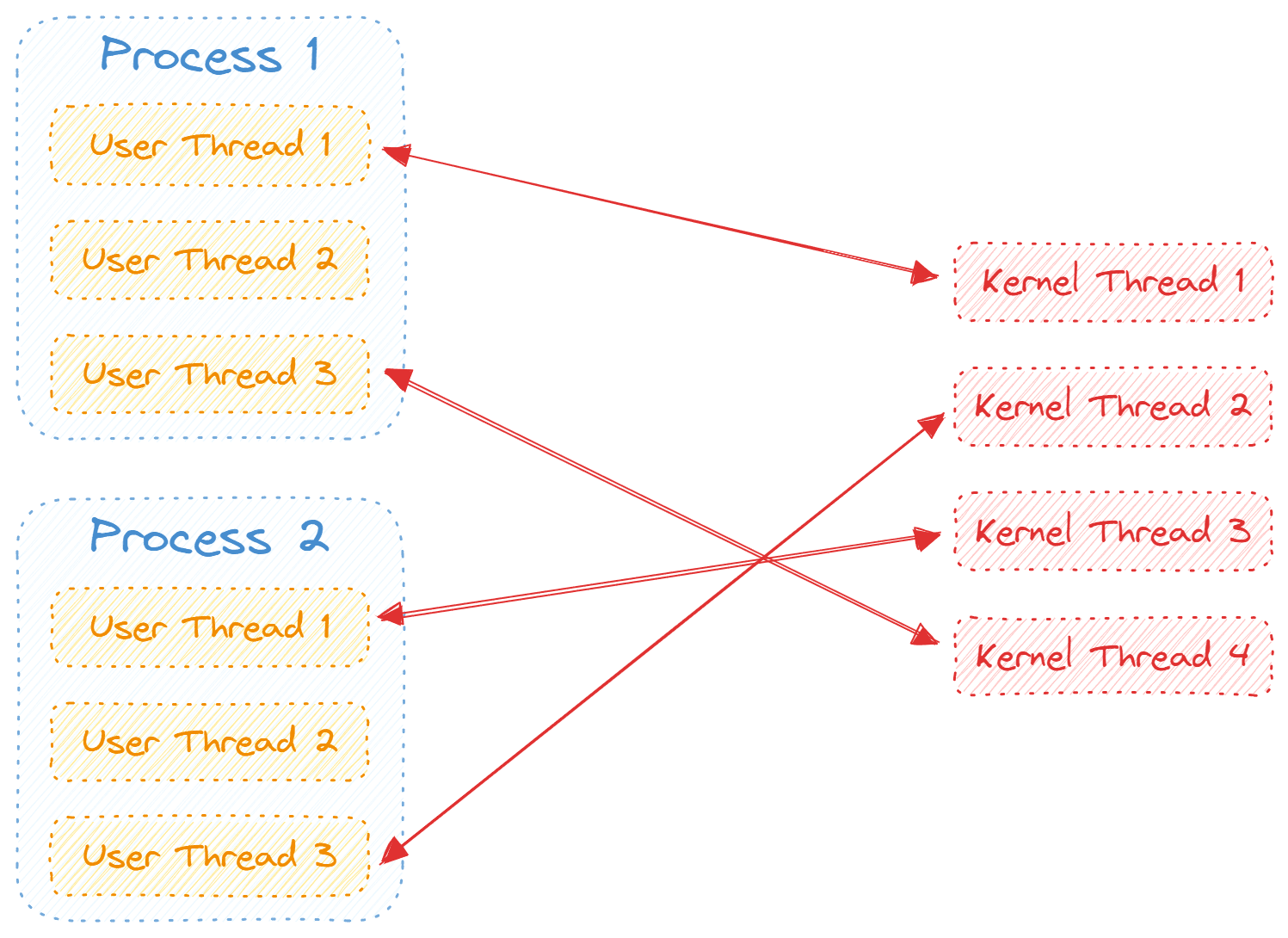
一个进程内部可以包含多个用户线程,这些用户线程是通过线程库创建的,受线程库调度。同一个进程内部的用户线程共享操作系统为该进程分配的诸如内存、文件、外设等资源。可以这样理解:线程库为开发者提供了一个简单易用的抽象模型,该模型可以方便开发者在其程序内部实现并行操作,提高程序的并发性。比如在开发代码编辑器时,我们可以利用线程库将文字渲染、语法检测(Lint)、自动提示(Auto Suggestion)、代码高亮(Highlight)等功能分配给多个单独的用户线程去执行而不用去考虑如何编排它们内部之间的关系。又由于这些用户线程是在代码编辑器这一进程内部创建的,它们之间可以共享资源,使得实现协作更加简单(如果采用多进程的方式实现功能的拆分,那么进程之间的资源共享、进程间通信等都会产生额外的性能开销,唯一的好处是某一个进程挂掉不会导致整个程序的崩溃,应该根据具体场景采用不同的实现方式)。
内核线程则是由操作系统创建的,受内核级别的调度器调度。对于操作系统而言,其只关心内核线程,也只能感受到内核线程的存在。用户线程对于操作系统而言是透明的,内核级别的调度器依据调度策略将内核线程分配给某个进程,进程内部到底是什么样的操作系统并不知道,而进程内部的用户线程之间的编排关系则是由线程库来调度的,分配给某个进程的内核线程究竟该执行哪段代码(哪个用户线程的代码逻辑)取决于线程库的调度(实际上并没有那么复杂,现实的实现中只需要交给内核调度器来调度即可,因为用户线程和内核线程是一对一映射的关系,内核线程调度器即可单独完成调度工作)。
相比于用户线程,内核线程的实现较为复杂,提供给用户使用的线程库是在内核提供的 API 基础上实现的,线程库的开发者并不需要关心不同处理器架构、不同操作系统之间的区别,只需要实现一个抽象的模型即可,而对于内核开发者而言,其需要做的事情就多得多了。
线程映射模型
线程映射模型是 Linux 线程模型的核心,其解决了该以怎样的方式将内核线程与用户线程联系起来的问题。之所以要将用户线程和内核线程映射起来是因为对于操作系统而言,其只知道内核线程的存在,内核级别的调度器在调度时会将内核线程指派到 CPU 的某个核心上执行,而 CPU 实际去执行的内核线程对应着内存中的哪部分代码则必须由一个相应的用户线程来指明,否则整个系统根本就无法正常运行。也可以这样理解:用户线程实际上只是一个逻辑上的虚拟线程,是为了方便用户实现程序的一种抽象,真正指派给 CPU 去执行的是内核线程,如果内核线程和用户线程之间没有对应的话,CPU 根本就不知道要去干什么。
内核线程和用户线程之间存在三种映射关系,即 1:1 映射、N:1 映射和 M:N 映射。1:1 映射表明对于每个用户线程,都有一个相应的内核线程与其对应。同理,N:1 映射将 N 个用户线程映射到 1 个内核线程上,而这种映射方式实际上是 M:N 映射的一个特例,即将 M 个用户线程映射到 N 个内核线程上。
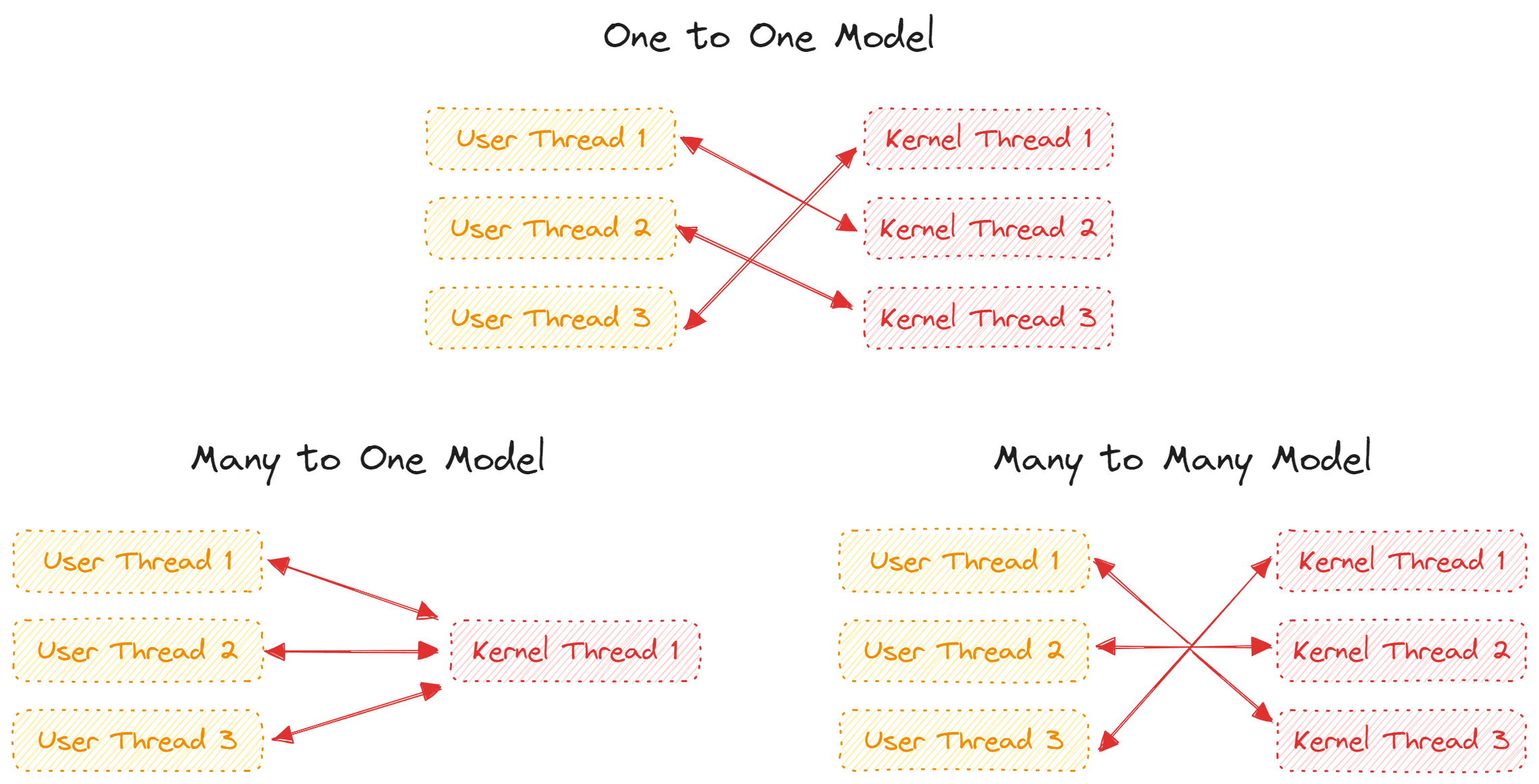
对于一对一映射而言,每个用户线程都对应着一个内核调度实体。此时实际上只需要一个内核级别的调度器即可完成调度。对于多对一或多对多映射而言,由于将多个用户线程映射到了某些内核线程上,用户线程之间需要进行协调以保证调度的公平性,同样的,对于内核线程而言,如何分配使得绑定在其上的用户线程之间保持协调一致也需要花费大量的工作。
三种映射模型的优缺点是非常明确的,首先一对一模型的实现难度相比于后两者而言简单了不少,但是由于一个用户线程对应一个内核线程,在用户线程较多的情况下会对系统性能造成一定的影响(此时内核线程也较多,内核调度器会频繁进行线程上下文切换导致系统整体性能下降)。多对一映射模型的好处是可以将一个进程内部的多个用户线程映射到同一个内核线程上,避免了用户态和内核态的频繁切换。但是倘若该内核线程由于 I/O 操作等出现了阻塞,则其对应的所有用户线程也会阻塞,降低了系统的并发性。多对多模型则避免了多对一模型的缺点,在某个内核线程阻塞时,用户线程还可以通过其绑定的备选内核线程继续获取到 CPU 资源,但是这种多对多模型要求额外的调度器来协调内核线程与用户线程、用户线程与用户线程之间的关系,增加额外开销的同时也加大了实现难度。
在当前 Linux 的线程模型实现中,采用的是一对一映射模型。至于为何采用一对一模型而不是多对多模型,Linux 社区早有讨论,Red Hat 在 The Native POSIX Thread Library for Linux 这篇文章中分别从设计理念、模型利弊、实际需求与实现难度等角度对采用何种模型以及为何采用一对一映射模型进行了阐述,非常值得一看,这里不再赘述。
内核线程和 CPU 核心之间的关系
我们之前提到,内核级线程调度器为内核线程指派 CPU 核心以执行内存中相应的代码逻辑。现代的 CPU 往往具有多个物理核心,每个物理核心又具有 2 个逻辑核心(超线程技术)。内核线程调度器在调度时首先通过线程调度策略从当前待调度的候选内核线程列表中选取一个内核线程,之后依据 CPU 核心的调度策略,挑选出一个 CPU 核心执行该内核线程对应的用户线程代码段。内核线程和 CPU 核心之间并没有明显的对应关系,二者只在调度时产生关联,不同的实现会有不同的内核线程与 CPU 核心调度策略。
此外,Linux 中存在着 CPU 亲和性(CPU Affinity)的概念,可以将某个用户线程 / 进程与某个 CPU 核心进行绑定,从而优化程序的整体执行效率:由于一个用户进程中可能会含有多个用户线程,这些用户线程又与多个内核线程一一对应,如果我们优先指派同一个 CPU 核心去执行属于同一进程的内核线程,那么该 CPU 核心内部的缓存命中率可以得到显著的提升,从而优化 CPU 的执行效率。这种优化方式的本质是强制规定进程 / 线程只能由特定的 CPU / CPU 核心来执行,比如:Redis 作为内存数据库,其对于内存读写效率十分敏感,因而其在启动时会通过配置 CPU 亲和性以提高内存读写效率,进而优化整体性能。