- 发布于
数据库是如何保证并发访问时的正确性的?
- 作者

- 作者
- 霍浩东
- @huohaodong
数据库管理系统
从使用者的角度来看,可以认为数据库管理系统(Database Management System,DBMS)提供了一个保证或抽象,即用户无需关注数据库的具体实现细节,只需参照数据库标准,编写对应的数据定义语言(Data Definition Language,DDL)来控制和定义数据库的表结构,之后通过数据操纵语言(Data Manipulation Language,DML)即可对数据表进行增删改查操作。
一个典型的 DBMS(以 MySQL 为例)由如下几个关键部分组成1:
- 连接池组件(Connection Pool):负责对用户的访问进行管理,涉及到安全认证、请求管理等方面;
- 管理服务和工具组件(Management Service & Utillties):数据库服务和工具管理组件,提供了用户权限设置,数据库备份与恢复等功能;
- SQL 接口组件(SQL Interface):向外暴露数据库的 DML 与 DDL 服务;
- 查询分析器组件(Parser):将用户编写的 DML 与 DDL 翻译为 DBMS 实际理解与执行的指令逻辑;
- 优化器组件(Query Optimizer):将查询分析器翻译后的指令进行优化以提高查询性能;
- 缓存组件(Cache or Buffer Pool):由于数据库中的数据是以页(Page)的形式组织和存储的,因此可以通过添加一层缓存来降低查询所需的磁盘 I/O 次数(主要是读取 B+ 树上对应的数据页)以提高数据库整体的查询性能2。应当注意的是,数据库中有多种不同类型的页,每种页可以有其对应的缓存池,不同的数据库对此亦有不同的实现和优化;
- 存储引擎(Storage Engine):对数据库的内存进行管理、实现索引算法及数据存储等。对于 MySQL 而言这一部分是可插拔(Pluggable)的,不同版本的 MySQL 有不同的默认存储引擎,比如 MySQL 8.0 之后默认使用支持事务(Transaction)的 InnoDB 作为其底层存储引擎。
一个典型的存储引擎(InnoDB)架构如下所示3:
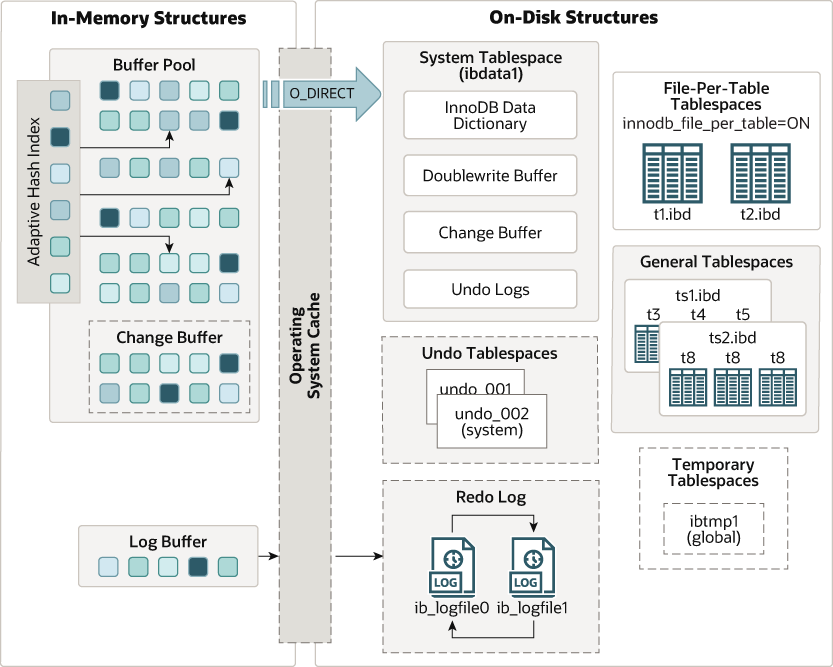
数据库并发访问时的正确性问题
我们在使用数据库时不可避免的会遇到多个客户端并发访问数据库的情况,即可能存在多个线程在某个时刻并发的读取或修改数据库表的逻辑结构,我们将数据库对于这类并发访问情况所作出的管理与保证称为并发控制(Concurrency Control),其主要通过并发控制协议(Concurrency Control Protocol)实现。并发控制是 DBMS 为用户提供的一种保证,即确保多个客户端同时访问共享数据时可以得到“正确”的结果,其主要有两层含义:逻辑正确性(Logical Correctness)与物理正确性(Physical Correctness)。
逻辑正确性是指对于用户而言,“我看到的数据是否是我期望看到的?”,比如用户将数据 A 修改为 1,紧接着再去读取该数据,其期望读取到 A 的值是 1 而不是其他值。DBMS 通过数据库事务(Transaction)来保证数据库的逻辑正确性。SQL 标准定义了事务隔离(Transaction Isolation)级别来约束在并发访问场景下可能出现的脏读(Dirty Read)、不可重复读(Non Repeatable read)与幻读(Phantom Read)4。用户则通过配置数据库的事务隔离级别来告诉数据库在并发访问的情况下,容忍出现脏读、不可重复读与幻读中的哪几种情况。
物理正确性是指对于 DBMS 而言,其如何在多个线程同时访问同一个数据结构(数据表、数据页等)时,保证或者说保护数据结构内部表示的正确性与可靠性。比如对于 MySQL 这类关系型数据库而言,其数据表在逻辑上呈现为为一棵 B+ 树,在物理上则表现为内存或磁盘上按照一定规则组织的一个个单独的二进制文件(Page)。B+ 树的中间节点存储了指向下一层节点位置(索引页或数据页)的指针,假设线程 A 和 线程 B 在同时遍历查询同一棵 B+ 树中的数据,某一时刻线程 A 通过中间节点拿到了其下一个要访问的节点的指针 P 并尝试读取对应的索引页(Index Page),此时若线程 B 在 A 执行读取操作之前见缝插针的将指针 P 对应的索引页删除,那么此时指针 P 就指向了一个未定义的区域,进而导致出现存储器区段错误(Segmentation Fault)。
从严谨的学术定义上来看,数据库管理系统和数据库是两种不同的概念,但是为了问题阐述的简明性,我接下来不会仔细区分数据库(Database)与数据库管理系统(DBMS),而是交叉使用两种术语,统一代指 DBMS 整体。
数据库中的并发控制
多个事务在并发执行的过程中很可能出现多个事务同时读取或修改同一数据对象的情况,为了保证数据库的逻辑正确性与物理正确性,需要数据库提供相应的并发控制机制。对于物理正确性而言,我们从线程的角度看待问题,通过锁来保护数据库内部的 In-Memory 数据结构。对于逻辑正确性而言,我们从事务本身的角度来看待问题,通过调整与检测事务内部的操作执行顺序与逻辑以保证多个事务交错执行时的逻辑正确性。
物理正确性保证
闩锁和锁
数据库中存在两种同步机制,锁(Lock)和闩锁(Latch)。锁主要用来在多个事务并发处理的场景下保护数据库的 In-Memory 数据结构,数据库事务在执行期间一直持有其访问的相应对象的锁。如果一个事务在执行过程中持有某些对象的锁,那么在该事务进行回滚(Rollback)时(因为某些特定情况)则需要确保将对应的对象回滚到加锁前的状态。比如在银行转账的场景下,用户 A 需要转账 100 元到用户 B 的账户中,一个简单的事务首先会从用户 A 的账户中扣除 100 元,之后再将这 100 元转入用户 B 的账户中,如果在钱转入用户 B 的账户之前银行系统刚好崩溃,那么在银行系统恢复时数据库需要能够回滚这些改动(这里只是举了一个简单且不太恰当的例子,实际上处理该场景的业务逻辑要复杂得多)。
闩锁本质上也是锁,只不过在 DBMS 的语境下,我们称其为闩锁以将与锁的概念区分开。闩锁用于在多线程并发访问的场景下保护 DBMS 内部数据的关键部分(Critical Section)。闩锁只在某一小段操作时间内持有且不需要负责在出现问题时回滚改动。比如在修改某个数据页时,线程会先去尝试持有数据页对应的闩锁,在修改数据之后再将闩锁释放。
锁和闩锁的区别可以总结如下5:
| Locks | Latches | |
|---|---|---|
| Separate... | User Transactions | Threads |
| Protect... | Database Connections | In-Memory Data Structures |
| During... | Entire Transactions | Critical Sections |
| Modes... | Shared, Exclusive, Update, Intention | Read, Write |
| Deadlock... | Detection & Resolution | Avoidance |
| ...by... | Waits-for, Timeout, Aborts | Coding Discipline |
| Kept in... | Lock Manager | Protected Data Structure |
闩锁的实现
闩锁实际上可以认为是一种互斥信号量(Mutex)。闩锁的实现可以借用操作系统或编程语言提供的信号量机制来实现:
// 使用操作系统或者编程语言提供的机制实现闩锁
Object mutex = new ReentrantReadWriteLock();
mutext.lock(); // 加闩锁
// 数据处理操作
mutext.unlock(); // 释放闩锁
使用操作系统或者语言内置的锁同步机制实现闩锁非常简单,但是可扩展性不强(控制权在操作系统/编程语言而不是 DBMS),难以在性能上做优化。
另外一种实现方式则是由 DBMS 本身去实现闩锁的逻辑,一种可行的方案是基于 CAS(Compare And Swap)实现自旋闩锁(Spin Latch)6。这种实现方式的效率较高,因为现代的 CPU 都内置了 CAS 指令,可以做到非常高的锁获取与释放的性能:
public class CompareAndSwapLock {
private AtomicBoolean locked = new AtomicBoolean(false);
// 释放锁
public void unlock() {
this.locked.set(false);
}
public void lock() {
// 自旋等待,直到获取到锁为止
while(!this.locked.compareAndSet(false, true)) {
// busy wait - until compareAndSet() succeeds
}
}
}
利用自旋锁实现闩锁逻辑的好处是其性能非常高,但是其在获取到闩锁之前会一直自旋消耗 CPU 资源,可扩展性同样不强且对于缓存不友好。
为了进一步优化自旋闩锁的性能,我们可以在自旋闩锁的基础上再抽象出一层锁逻辑,即读写闩锁(Reader-Writer Latch)。作为一种读写锁7,读写闩锁允许多个 Reader 同时读取数据,但是不允许 Reader 和 Writer 同时读写数据。读写锁的典型实现是通过一个读队列与写队列来实现的:如果一个线程想要读数据,那么其要先查看当前是否有其他线程在写,如果有则需要阻塞到写队列为空。同样的,如果一个线程想要写数据,那么其要先查看当前是否有其他线程在读数据,如果有则需要阻塞到读队列为空为止。对于读写闩锁而言,我们需要小心设计队列之间的交互方式以避免读饿死(Reader Starvation)或写饿死(Writer Starvation)的情况。
闩锁在哈希索引中的应用
DBMS 中绝大多数的数据或者元数据(Meta Data)都以哈希索引(Hash Index)、B+ 树索引(B+ Tree Index)或者哈希表(Hash Table)的形式存储与实现。实际上,我们可以在数据库的哈希索引(Hash Index)或者哈希表(Hash Table)中使用闩锁来保护其数据结构在多线程访问下的安全性。
对于哈希表而言,不管其底层采用何种方式处理哈希碰撞(Hash Collision),多个线程访问哈希表时都遵循着某种查询顺序扫描哈希表以找到其想要的数据。对于通过链地址法(Separate Chaining)处理哈希碰撞的哈希表而言,线程只需要在访问前对某个 Page 或 Slot 加闩锁即可。而对于通过线性探测法(Linear Probing)处理哈希碰撞的哈希表而言,由于其哈希表本质上可以看作是一个环形的缓存,因此同样只需要在访问对应的 Page 或 Slot 时加锁即可。在对哈希表进行扩容(Resize)时需要重新计算哈希表中每个元素的哈希值以实现哈希表的重映射(Rehash),我们同样可以在哈希表扩容时使用一个全局的闩锁来保证此时并发访问的安全性。
加在哈希表上的闩锁可以有两种不同的粒度:页闩锁(Page Latch)和槽闩锁(Slot Latch,也可以称之为行锁)。页闩锁是加在单独的页上的,每个页都有其对应的读写闩锁来保护其数据结构的安全性,页闩锁的细粒度下,每个线程在读写页时都需要先获取对应的读写闩锁。而槽闩锁则更进一步,在元组(Tuple,又是又称为 Record 或 Data Row)的粒度上对哈希表加锁。
由于数据库中的表是以一个或多个数据页的形式组成的,每个数据页内部又可以包含多个数据槽8,而数据槽又对应着数据表中的某行或某几列数据,因此页闩锁可以认为是加在数据库中某个数据表的某几行上的锁,而槽闩锁则可以认为是加在某个数据行或某几列数据上的锁。

页闩锁和槽闩锁的选择需要在计算和存储上做取舍。对于页闩锁而言,我们只需要为每一个页维护一个页闩锁即可,数据库总体的闩锁数量不会太多,对于存储比较友好,但是在并行性能上有所下降。而对于槽闩锁,我们几乎需要为数据表中的每一行都维护一个槽闩锁,因而会占用大量的存储空间。此外,线程在顺序扫描数据页时,每访问一行就需要获取并释放对应的槽闩锁,性能上也会有所下降。比如为了方便用户对数据性能进行优化,像 InnoDB 这样的存储引擎提供了多种选项来控制闩锁的粒度,包括行锁、表锁和页锁。
闩锁在 B+ 树索引中的应用
考虑如下场景:线程 A 和 B 同时访问同一棵 B+ 树,线程 B 想要向 B+ 树中插入一个数据,线程 A 则是想要读取 B+ 树中的一个数据。此时假设线程 B 首先完成了插入操作,且此插入操作导致 B+ 树某个节点已满,进而需要进行节点的分裂和合并操作。在此过程中,如果没有闩锁的保护,线程 A 可能无法访问到数据或访问到未定义的内存区域(我们在之前提到的存储器区段错误)。数据库中几乎所有数据表都以 B+ 树索引的逻辑结构来存储,且在物理上也是按照 B+ 树的结构来存储的,在多线程并发场景下保护 B+ 树的逻辑结构和物理结构的“正确性”(或者说是一致性)是数据库可以正常工作的前提。
使用闩锁保护 B+ 树索引结构的算法较多且非常复杂,不同的 DBMS 对此亦有不同的实现9。一个朴素的算法思想为:每个线程在访问 B+ 树节点时首先对该节点加锁,在完成所需操作后再释放锁。此时相当于每个线程独享一棵 B+ 树结构,降低了计算的并行性,不利于 DBMS 的整体性能。一种优化方案是每个线程在加锁后在之后通过安全性分析来靠考虑是否释放之前拿到的某些节点的锁,如果线程觉得某个时刻释放某些节点的锁不会引发并发问题,则会释放对应的锁。
逻辑正确性保证
我们之前提到,DBMS 通过事务以及调整和验证事务之间内部操作的顺序来保证数据库的逻辑正确性与事务的 ACID 特性10。数据库的并发控制主要通过并发控制协议实现,常见的并发控制协议可以分为如下几类:
- 基于锁(Lock-Based)的并发控制协议:通过锁来控制事务之间操作的执行顺序。事务在执行操作时会先对数据加锁并在操作结束后释放锁。所有锁的获取都需要事务主动向全局的锁管理器(Lock Manager)请求获取。
- 基于时间戳(Timestamp-Based)的并发控制协议:通过时间戳来序列化事务的执行顺序,基于时间戳的并发控制协议会确保事务之间冲突的读写操作按照某种时间戳循序执行,依次达到某种全局顺序,从而满足逻辑正确性。
- 基于验证(Validation-Based)的并发控制协议:又被称作乐观的并发控制(Optimistic Concurrency Control)。之所以称之为“乐观”是由于这类并发控制协议提出了一大前提:“大多数事务在并发执行时是互不影响的”且在事务执行的过程中不进行冲突检测,在事务结束之前所有改动都不会更新到数据库中,并在最后的验证(Validation)阶段判断是否有任何事务违反了可串行性11(Serializability)。
在数据库事务并发控制中,如果事务调度(Schedule)的最终结果等同于某种串行执行的结果,则认为该事务调度为可串行化(Serializable)的。可串行性可以理解为所有事务的操作按照某种调度规则交错执行后,每个操作在执行过程中看到的结果是一致的,即假如事务 A 在某个时刻将数据修改为 1,那么按照调度顺序,另外一个事务 B 在下一时刻的读操作则应该可以看到上一时刻事务 A 对数据的修改结果。
可串行性可以这样理解:如果每个事务本身是正确的(符合事务 ACID 的 Integrity 特性),那么意味着对这些事务的任何在时间上不重合的调度都是合法的,即通过对多个事务内部的操作进行串行化处理,最终得到的事务执行顺序是符合每个事务本身的预期的,从而提供了一种事务之间隔离了的假象,即实现了事务的隔离性。
值得注意的是,事务调度只是保证了事务本身执行逻辑的正确性,并没有保证事务在调度后得到的业务逻辑是正确的,数据库本身也并不知道某个事务内部的操作所对应的业务逻辑是怎样的。并发控制协议只是面向多个并发执行的事务提供了一种可能的执行顺序,由此实现了事务之间的隔离性。
读锁和写锁
数据库中的锁分为读锁和写锁两种,拿到读锁的事务只可以对数据进行读操作,且其他想要读该数据的事务也可以读取数据,因此读锁又被称为共享锁(Shared Lock)。写锁又被称为排它锁(Exclusive Lock),其不允许对上锁对象同时进行读写操作。这里很像我们之前提到的读写闩锁的逻辑,基于锁的并发控制协议通过对数据加上读写或写锁以使得多个事务操作之间达到某种序列化的执行顺序。读锁和写锁的相容性矩阵如下所示:
| 锁相容性矩阵 | 读锁 | 写锁 |
|---|---|---|
| 读锁 | ✅ | ❎ |
| 写锁 | ❎ | ❎ |
需要注意的是如果某个事务在获取锁的过程中遇到了根据相容性矩阵中不允许的情形,则事务会一直忙等到获取到锁为止,另外这里的忙等逻辑可以用自旋锁实现。
两阶段锁协议
两阶段锁(Two Phase Locking,2PL)协议是一种基于锁的经典数据库事务并发控制协议12,其可以看作是一种悲观的(Pessimistic)并发控制协议。2PL 的主要目的是确保事务的可串行性,其在工作时主要分为两个阶段:扩张阶段(Expanding phase)和收缩阶段(Shrinking phase)13。在扩张阶段,每个事务都可以获取锁但是不能释放锁,而在收缩阶段,每个事务只能释放锁而不能获取锁,如下图所示:

2PL 通过限定锁的获取规则(即扩展和收缩)来保证多个事务按照某种顺序线性的执行它们的内部操作,以此达到多个事务之间的可串行性,进而保证了事务的正确性。虽然 2PL 保证了所有事务按照某种顺序串行执行,但是其并没有保证事务之间不会产生死锁,因而需要由全局的 Lock Manager 或死锁检测器来检测出现的死锁,并按照某种仲裁规则恢复处于死锁状态下的事务。此外,2PL 还会导致出现数据的脏读(因为锁释放是在事务 Commit 之前)与级联回滚(Cascading Rollback)问题。
基于 2PL 还衍生出了多种并发控制协议,其中比较典型的是严格两阶段锁(Strict Two-Phase Locking)协议,其在 2PL 的基础上又加了一层限制,即每个事务只在事务提交成功后(Committed)才会释放锁,而不是在事务执行的过程中释放锁,因而解决了 2PL 的脏读和级联回滚问题。
基于时间戳的并发控制协议
基于时间戳的并发控制协议则通过操作系统的全局时间或定时器来串行化并发执行的事务,可以看作是一种乐观的(Optimistic)并发控制协议。在此类协议中,其为每个数据分配了两个时间戳信息以记录该数据上次被某个事务成功读/写的时间信息,如果一个事务在执行时发现其试图访问某个“未来的数据”,则其会被打断并回滚,并在 DBMS 为该事务分配一个新的时间戳后重新执行。
基于时间戳的并发控制协议无需担心死锁的问题,因为其在事务执行操作过程中就已经确定执行顺序,因而确保了冲突的读写操作都会按照时间顺序执行。这类并发控制协议的缺点是可能会出现饿死的情况:某个事务一直读到“未来的数据”因而一直被打断。
基于验证的并发控制协议
基于验证的并发控制协议作了如下假设,即“大多数事务在并发执行时是互不影响的”。该类协议将事务的执行分为了读写扥更多个部分,在事务读阶段,DBMS 会尝试执行所有事务的读操作,并将得到的临时数据存储到临时区域。之后 DBMS 会去验证是否有某个事务在其他事务的读阶段期间修改了某些被读到的数据,如果验证不通过则进入事务写阶段,即所有进入写阶段的事务将读阶段的临时数据写入数据库。不难理解,基于验证的并发控制协议是一种乐观的协议,其在验证阶段通过检测是否出现了违反事务可串行性的读写重叠操作来保证每个事务的逻辑正确性。
多版本并发控制协议
由于 2PL 的高性能,以往几乎所有的数据库系统都采用了 2PL 来实现事务的串行化。而随着技术的发展,目前主流的数据库则主要采用多版本并发控制(Multiversion Concurrency Control,MVCC) 来实现事务的串行化。MVCC 的核心思想非常朴素:每个事务都拥有一份属于自己的数据快照,事务的读操作不会阻塞写操作,同样,写操作也不会阻塞读操作。在 MVCC 中,DBMS 会为每个数据分配一个自增的全局版本号与时间戳,并为每个事务操作得到的数据副本也分配对应的读/写时间戳。当事务要更新数据时,其不会直接用新数据覆盖原始数据,而是创建一个该数据的副本,并存储多个版本的数据副本。事务在读写数据时的逻辑和基于时间戳的并发控制协议一致,唯一区别是事务会按照多个数据副本的时间戳顺序来选择数据读取的版本,而不是只有像原始的基于时间戳的协议那样只有一个可选的数据版本,进而减少了事务被打断回滚的次数,缓解了事务饿死的情况。MVCC 的主要缺点是需要为数据额外维护时间戳和版本号信息,会占用额外的存储空间且增加了信息的读写量。
MySQL 和 Redis 的并发控制
InnoDB 主要采用 MVCC 实现事务的并发控制14,且只在 Serializable 隔离级别中使用 2PL。对于 Redis 这类 NoSQL 键值(Key-Value,KV)内存数据库而言,其将用户定义的数据结构以键值对的形式存储在内存中进行管理。并发控制保证了 Redis 不会访问到未定义的内存区域。
Redis 实现并发控制的方案十分简单粗暴:采用单线程模型来处理所有控制请求,并按照命令的入队顺序执行,其结果相当于按照某种全局的顺序执行客户端发来的指令。由于指令执行的过程中只有一个主线程参与,因而不存在竞态(Race Condition)条件,自然不会引发并发读写同一数据结构导致的问题,从而保证了物理正确性。此外,Redis 还提供了锁机制与事务供用户使用,从而保证了逻辑正确性。应当注意的是,Redis 虽然在其 6.0 版本引入了多线程来处理网络 I/O 请求,但是命令的执行仍是由一个唯一的主线程负责,因此同样不存在逻辑正确性的问题15。
总结
- DBMS 通过锁和并发控制协议共同保证了并发访问时的正确性;
- 数据库并发访问时的正确性分为物理正确性和逻辑正确性;
- 物理正确性通过锁机制实现,用以保护数据库的 In-Memory 数据结构;
- 逻辑正确性通过事务的并发控制协议实现,通过将事务串行化以保证事务之间的隔离性以及事务本身的 Integrity,进而保证了多个事务并发执行时的逻辑正确性;
- 事务的并发控制协议并不保证业务逻辑的正确性,想要满足业务逻辑的正确性还需要根据业务逻辑来配置事务的隔离级别(比如对于敏感业务想要避免幻读就需要设置事务隔离级别为 Serializable,此时 DBMS 保证所有事务的最终执行结果都与每个事务按顺序执行的结果相同);
- 目前主流的数据库主要采用 MVCC 实现并发控制,不同的数据库对此有不同的优化与实现方式,但是基本思想是相通的;
- MySQL 默认隔离级别是 Repeatable Read,会存在幻读问题,并不能避免写覆盖问题;
- MySQL 在 Serializable 隔离级别以下使用 MVCC,Serializable 级别使用 2PL。